

Данная история о том, почему на проектах комплексного внедрения системы управления проектами в смете должна присутствовать строчка под названием «Подготовка данных к переносу». Ибо мы её один раз пропустили и от этого получился сей прекрасный опыт, который и описываем в этой статье. Всему есть своя польза.
Описанное здесь – правда, произошедшая на одном из наших проектов, где нужно было сделать комплексное внедрение системы ПланФикс с заведением туда же всей номенклатурной информации. Просто в тот момент мы не знали, с чем нам придётся столкнуться. Потому и строчки такой в смете не было J. Но пусть будет эта статья всем уроком при работе на проектах такого масштаба. А клиентам – обоснование стоимости данной работы. Потому что вообще, корректность информации в системе – один из важнейших факторов успешного внедрения системы.
Итак, погнали…
Сразу отметим, что подобная ситуация может произойти на абсолютно любом большом проекте, потому что мало кто из клиентов может на своей стороне своими силами подготовить 100% корректные данные для переноса в систему, особенно если они никогда и не структурировали всю информацию, с которой работают. Ну работают как-то и ладно, бизнес идёт. Но в какой-то момент всё равно кому-то придётся с этой всей информацией разобраться. И тут стоит отметить, что руководство данного проекта (а также сотрудники, участвующие в процессе работы) было настолько адекватным и здраво оценивающим ситуацию, что совместными усилиями мы всё же достигли тут результата. За что им огромный респект.
В начале статьи – кадр из видео (оно будет ниже сразу), которое идеально иллюстрирует ситуацию с заведением информации в систему. Ты едешь-едешь-едешь (текущую работу компании на время внедрения никто не отменял), прокладывая рельсы прямо перед поездом (ведь всё же работу нужно ставить на новые рельсы), а потом вдруг понимаешь, что уехал уже не туда (понимание того, что предоставленная информация со стороны клиента не 100% корректная), но обратного пути уже нет, рельсы за тобой «сожжены». И ты видишь, что где-то там, в самом начале твоего пути (и видео) существует второй путь (как можно было бы делать иначе), по которому и надо было ехать. Но сейчас единственный вариант – только вперёд.
Видео:
Кратко о бизнесе заказчика и задаче:
Бизнес – производство одежды под своим брендом
Задача – перенести текущую ассортиментную базу в систему, перенести всю номенклатуру тканей и фурнитуры в систему (это точка Б)
Точка А – набор гугл-доков с описанием ассортимента и общими словами про номенклатуру по модели. Ну чтобы вы понимали, если сейчас в системе номенклатурная позиция может выглядеть как «[Пенье] [320 г/м2] [80% хлопок; 20% ПЭ] [Футер 3-х нитка начес БУКЛЕ]», то в паспорте модели оно могло быть описано как «Футер 3хнитка». И гадай потом закупщик, что именно имелось ввиду. Ну если закупщик тут работает уже не первый год, то он сообразит по памяти. А если новый придёт? Всё, труба.
Кстати, «труба» уже как-то наступала, когда руководство попыталось нанять второго закупщика. Продержался он меньше месяца и сбежал со словами «да у вас тут ничего не разберёшь». Сбежал, успев добавить за время своего присутствия ещё больше хаоса в общий котёл информации. Короче, весело.
Ну да ладно, приступим к описанию того, как этот хаос привёлся к порядку.
Перед тем, как заносить большие объёмы информации в систему, нужно продумать архитектуру этой базы данных. В случае с ПланФиксом – это продумать структуру справочников. Начнём с текущей базы моделей клиента. Если раньше вся база была в Эксельке и имела такой вид:
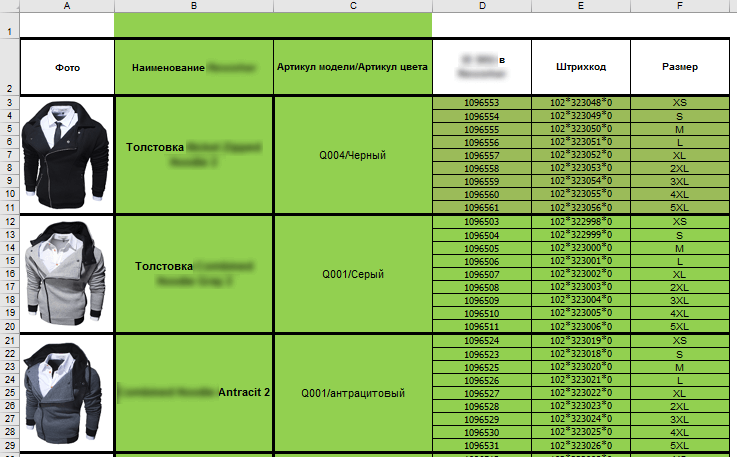
То в системе это сейчас состоит из аж 9 справочников!
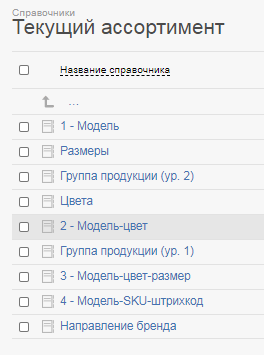
Такое разнесение информации даёт очень крутые возможности по работе с нею в системе. Можно настраивать планировщики с категоризацией по группе продукции:
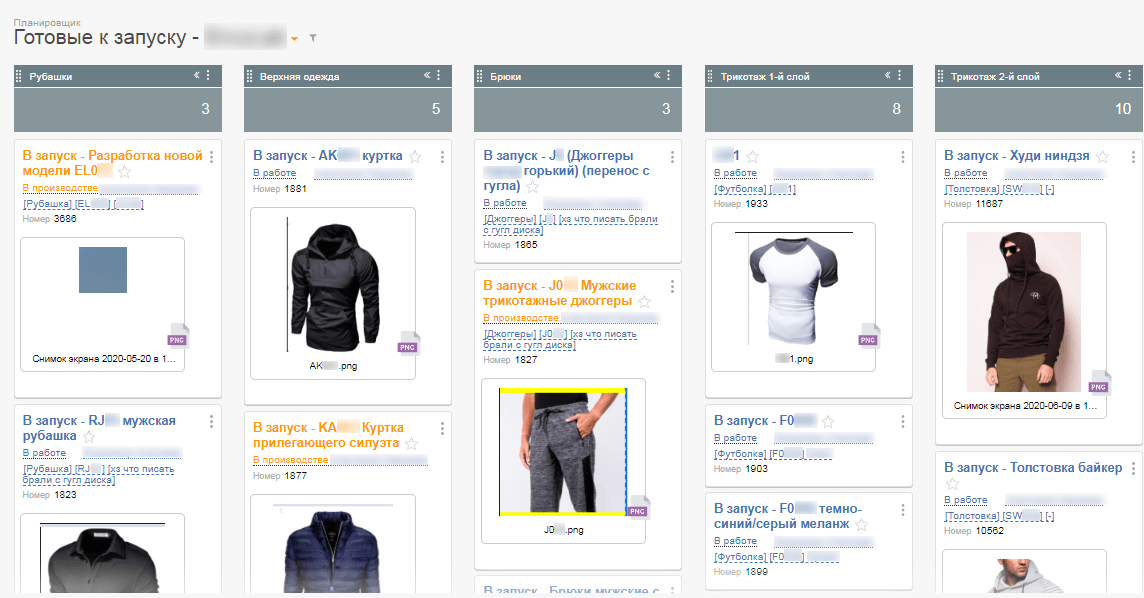
Можно в нужных местах в задаче указывать конкретную модель, без деталей про размер и прочее (ибо не надо там это):
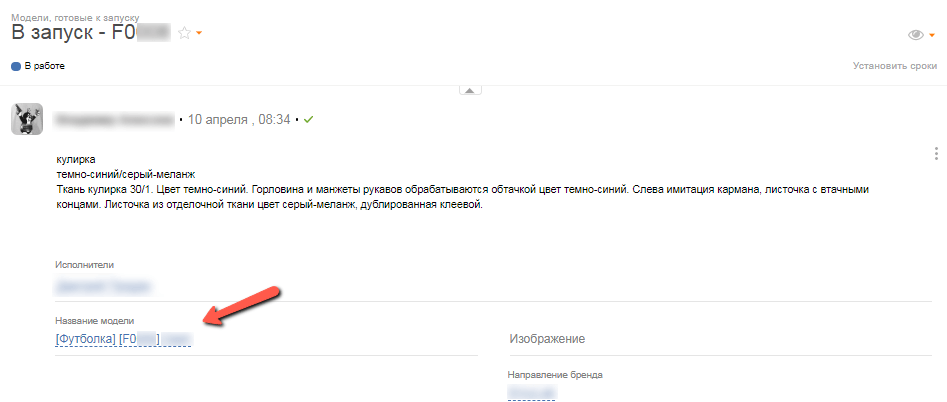
Да и много чего ещё.
Но одна из ключевых возможностей – это распределение прав доступа так, чтобы никто не мог «убить» всю эту базу (в случае с гугл-доком это можно было сделать за несколько секунд). И чтобы каждый нужный сотрудник заполнял лишь свой кусок информации по модели. Например, саму модель и цвета по ней заносит продакт-менеджер на этапе разработки. А вот уже конкретные размеры и ID со склада – операционный менеджер. А все другие вообще могут лишь читать эту информацию, без прав на редактирование.
Начали мы перенос с того, что со словами «тут всё есть» нам как раз дали гугл-док и несколько экселек с информацией про модели. Что-то в разработке, что-то уже разработано, но ещё не запущено в производство, а что-то постоянно отшивается как стандартный тираж. И всё это надо занести в систему. И в любой момент времени модель может перекочевать из разработки в уже запущенные. Наша задача – всё это отследить и успеть корректно перенести в базу. Тут была работа с 2х сторон:
- Мы в файлах цветом помечали те позиции, которые уже перенесены в систему
- Сотрудники со своей стороны сообщали, если добавляли в файл новые позиции
Пункт 2 работал не всегда, поэтому мы тщательно бдили над тем, что происходит в файлах. Это больше наша ответственность, чем клиента.
Особенно важно было в конце, когда вся информация уже в системе и новые модели надо заносить уже лишь в систему, предотвратить по привычке добавление информации в старые файлы. А это было. И не раз, и не два. Ну привычка – дело такое, её сложно поменять у коллектива. Тем более просто отключить доступ к файлу мы не могли, т.к. там порой были другие листы с информацией, которая ещё не в системе.
Поэтому нам ничего не оставалось, как применять супер-последние технологии по предотвращению человеческих действий, разработанные в кулуарах нашей лаборатории по работе с коллективом клиента – визуальный блок при открытии файла :). Всё гениальное всегда просто. Зацените жёлтый большой блок:
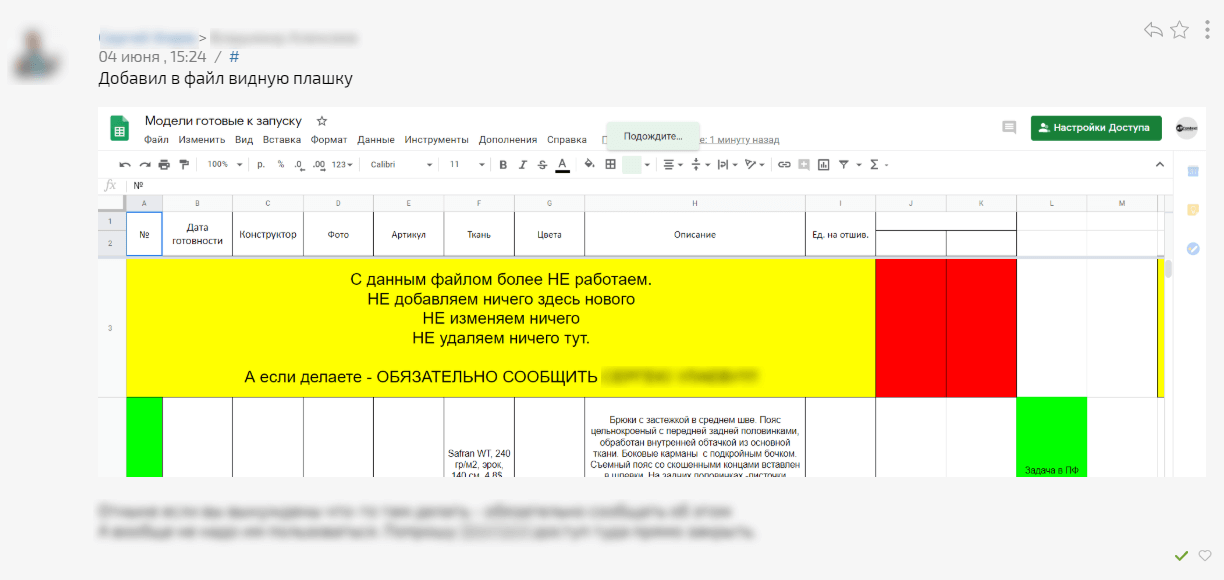
Или же в сами папки в гугл-диске (а папок там нехило было) клали документы, которые должны были привлечь внимание на случай захода сюда сотрудника:
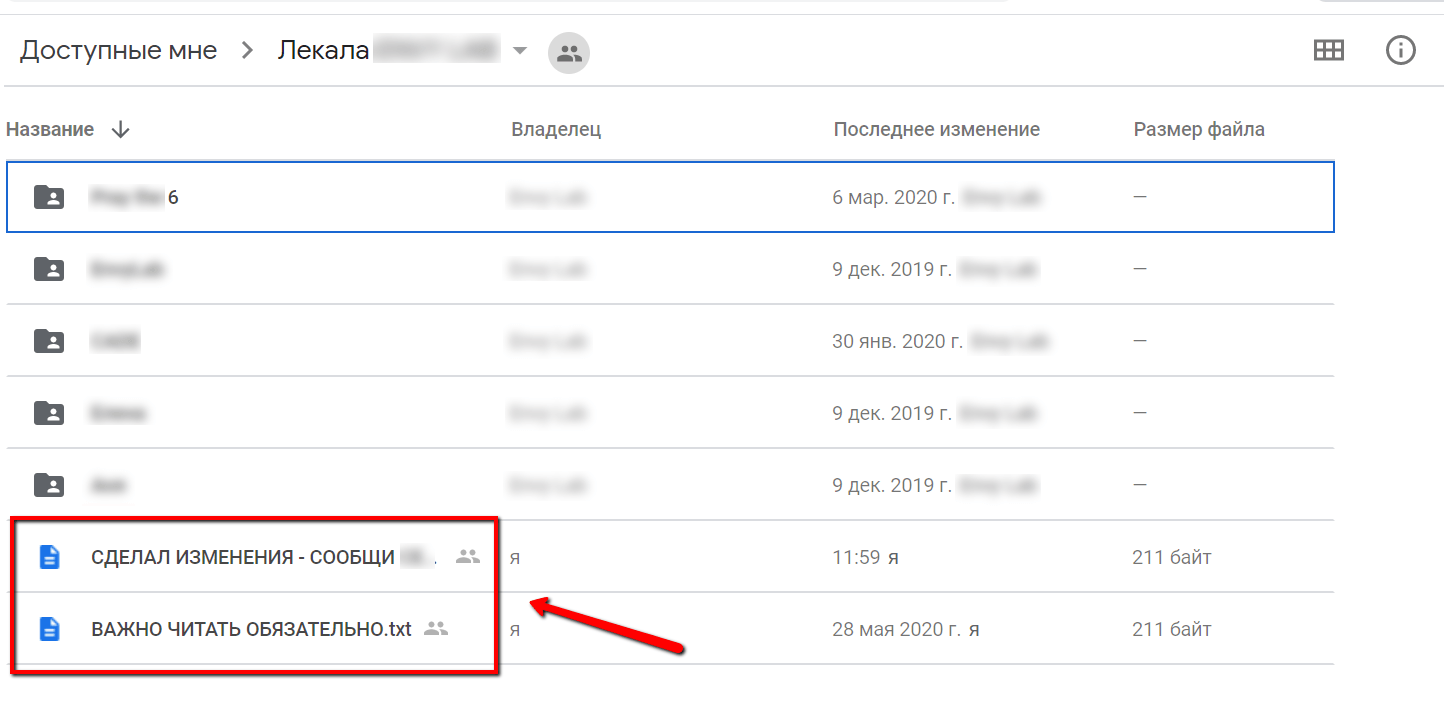
К слову, такая схема работала отлично и после появления таких сообщений во всех нужных файлах/папках, прекратились случаи добавления новой информации не туда, куда надо.
В процессе переноса ассортимента в систему было довольно много неожиданных моментов, все уже не упомнишь, но из особо важных был такие:
1) Модель могла находиться в файле разработки, готовой модели…а ещё и в тираже. Ну потому что там тоже не особо прибирались.
2) На одну модель могло быть несколько внутренних артикулов. И это особое «удовольствие», когда в одном файле видишь один артикул, а в другом – другой. У меня вот у сына есть книжки, где надо нарисовать линию между рисунком животного и его едой. Вот тут мы чувствовали себя примерно так же. Соедини 2 артикула в одну модель :). На рисунке ниже подтверждение факта наличия данной проблемы:

3) Артикулы вообще могли быть перепутаны между собой по моделям. В голове все помнят актуальную информацию. А вот в файлах – неразбериха:
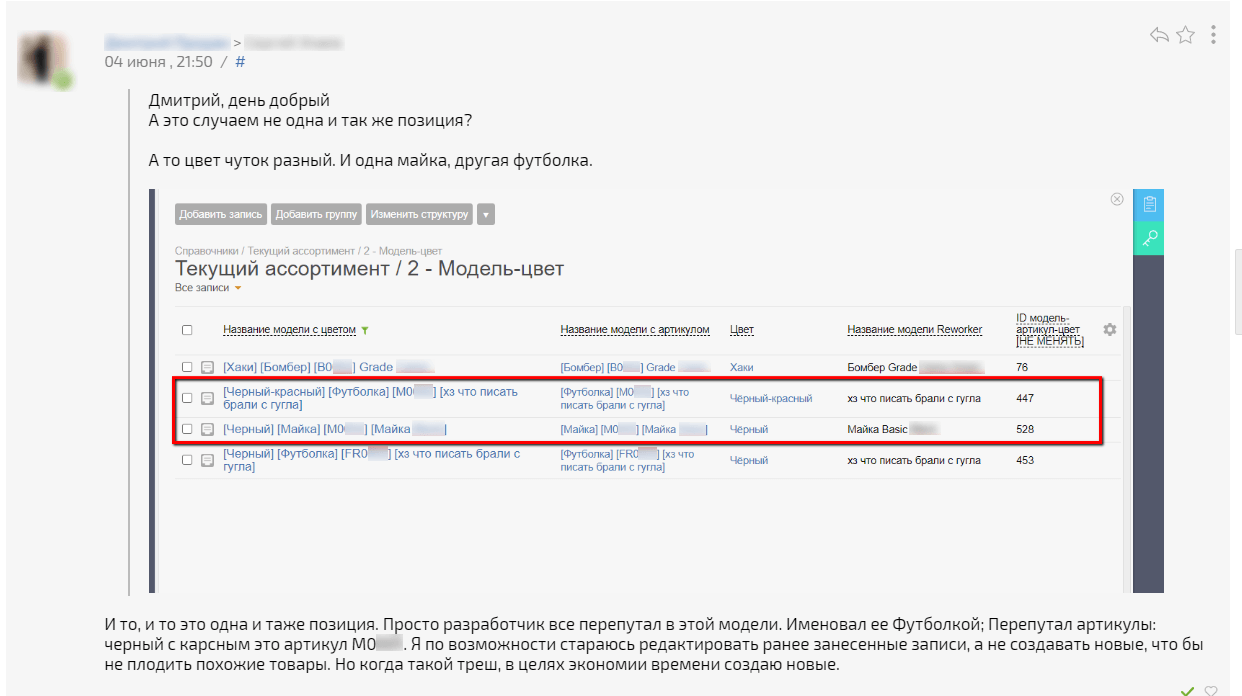
4) И много прочей мелочи, похожей сути
Но вообще разобраться с базой ассортимента – это «цветочки» по сравнению с базой тканей и фурнитуры. И здесь мы уделили намного больше времени на то, чтобы продумать архитектуру справочников, понимая, что соверши ошибку – и придётся мучительно перелопачивать кучу информацией, причем в ручном режиме, т.к. справочники – не сильная сторона ПланФикса, особенно по части какой-либо автоматики на их изменения. Хотя, уверен, что временно и это лишь вопрос времени.
Для начала мы собрали всю информацию (как мы тогда думали, что всю. Хо-хо, как мы ошибались) по названиям тканей и фурнитуры. Дополнили это пожеланиями со стороны руководства о том, что обязательно нужно дополнительно отслеживать. И получили…несоответствие данных :). Мы собирали информацию кусочно от разных людей и сильно (первое время сильно, потом уже привыкли) удивлялись, когда один человек корректирует информацию от другого человека. Кто там в итоге прав-то?
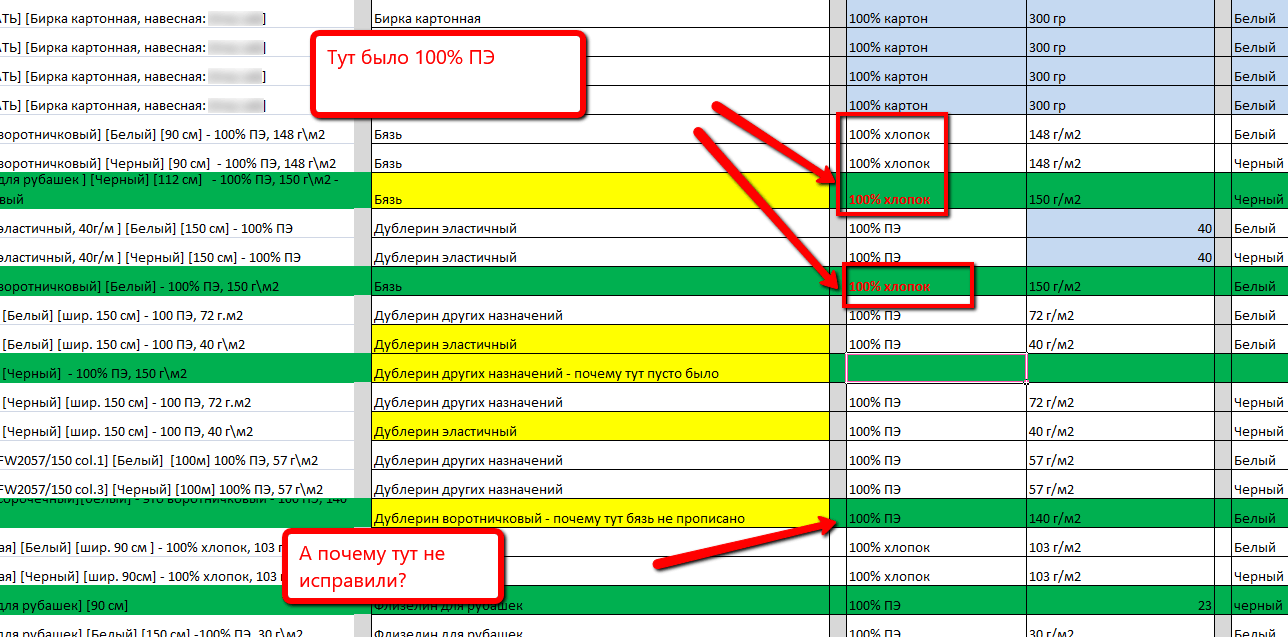
Мы это отследили и начали «допытывать» всех нужных сотрудников по абсолютно каждой позиции, где были какие-либо вопросы. Кто-то отвечал нам довольно «холодно», а кто-то поддерживал наши старания и веру в успех:

Клиент держал все номенклатурные позиции в эксельке, где 1 строка = 1 позиция. Это довольно удобно для быстрой работы с файлом, когда нужно чего-то найти или кому-то скопировать для контекста общения. Не забывая дополнить это обязательной важной информацией, взятой из головы.
Т.е. очень легко между нами мог получаться такой разговор:
– А как зовётся ткань для этой модели?
– Нихат подвяз 3хнитка
– Эммм…а подетальнее можно?
– А что детальное? Нихат подвяз 3хнитка. Ну цвет хаки для этой модели.
Наша внутренняя чуйка в этот момент подавала красный сигнал «тревоги», предвещая непонимание происходящего. И потом, распутывая клубок, оказывалось, что Нихат – это поставщик. Да ещё и поставщик чего-нибудь уникального, поэтому нам бы обязательно знать не просто название «подвяз 3хнитка», но и состав и плотность. А ещё ширину рулона.
А суть в том, что когда тебе говорят «Нихат подвяз 3хнитка», ты НЕ знаешь, что:
- Нихат – это поставщик, а не название ткани
- Подвяз – это не какое-то свойство (типа цвета), а составляющая названия
Зато сотрудники настолько привыкли объединять всё это в одно словосочетание, что для них понятия «название ткани», «название ткани со свойствами» и «название ткани со свойствами и поставщиком» – абсолютно одинаковые вещи. Нам же надо всё это разделять.
И порой нужную информацию мы узнавали уже в сааааааамом конце, когда перенесли почти всю информацию. Например тут, как оказалось, Dublin – это не общее название ткани, а всё же конкретный артикул ткани у конкретного поставщика. Вот кто мог знать, не работая с этим каждый день? Сотрудники компании, хоть и старались, но с первого раза не могли расчленить эту информацию по разным «полочкам». Тут где-то только на 4-ой проверке (!!!) общей информации выявился этот момент.

Один из сотрудников также в переписке подтверждал наличие текущих проблем с базой номенклатур:

Забегая чуть вперёд, скажем, что в итоге вместо одной строки по каждой позиции у нас вышла такая архитектура справочников по всей номенклатуре:
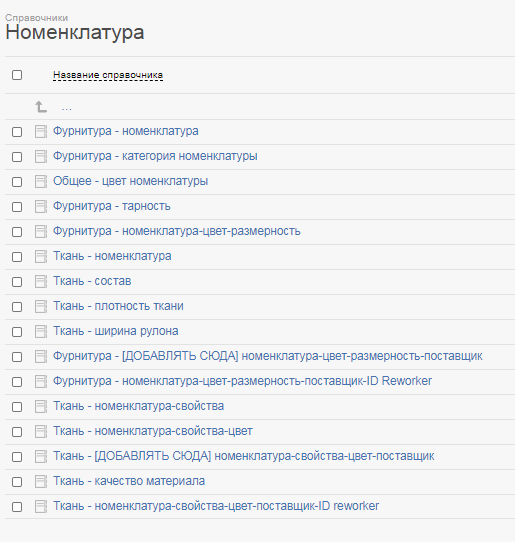
Причем это уже последняя версия справочников, т.к. в какой-то момент получения всей информации мы поняли, что обладая на старте неполной информацией, мы сделали чуток не ту архитектуру. И начали заносить информацию по всем уровням справочников. А потом…потом оказалось, что надо менять структуру и вручную менять уже занесённые записи. К глазам подкатывали слёзы в тот момент, когда мы это поняли. Именно тогда пришла идея сделать видео, что вы видели в начале статьи. Именно тогда мы в голове увидели тот верный, изначальный путь, который мы «проехали» в самом начале, а теперь нам надо как-то вывернуть на ту дорогу, но двигаясь лишь вперёд. Снести всё занесённое уже было нельзя, т.к. часть информации уже использовалась в задачах, с которыми работали сотрудники.
Это один из важных уроков – сначала получите 100% полную информацию по всем номенклатурам, и лишь потом делайте архитектуру справочников. Ну или понимайте риски от способа «делаем как есть, там разберёмся». Потому что он тоже иногда подойдёт, когда скорость важнее. В нашем случае у нас время было, мы просто пошли не тем путём, ожидая, что изначально получим корректные данные.
И тут, кстати, мы подошли к центральной мысли этой статьи (ибо дальше уже будет художественное описание нашего подхода к работе)
*** *** *** ***
Корректность предоставления информации по номенклатуре и ассортименту – это один из важнейших факторов успешного внедрения!
*** *** *** ***
Может ли клиент на своей стороне самостоятельно подготовить 100% корректные данные, необходимые для занесения в систему? Мы считаем, что НЕТ. Клиенту деньги делать надо и решать текущие операционные задачи.
Должен ли клиент участвовать в процессе подготовки данных – ДА! Но контроль происходящего и понимание того, что все данные связываются между собой – ответственность наша (компании-интегратора). Это мы должны направлять ход мысли клиента на «путь истинный», т.к. он настолько привык в одно предложение закидывать и поставщика, и свойства номенклатуры, что разделить это на разные части самостоятельно очень сложно, если вообще возможно.
Должен ли клиент утверждать итоговый список полученной номенклатуры – тут тоже ДА, т.к. как ни крути, никто не знает, где идеал и всегда может вылезти что-то неожиданное. Это очевидная вещь, которую тоже все стороны должны понимать.
Можно, конечно, встать на позицию «Наша хата с краю, нам что дали – с тем и работаем. А коли дали неверно – ну их проблемы». И потом даже юридически защищать эту позицию и быть (чисто юридически) правым. Но какой в этом смысл, если вы с клиентом «плывёте в одной лодке» и вам тоже важен результат и нельзя просто смотреть на то, как клиент нечаянно делает дыры в лодке.

Если, конечно, интегратор тоже за результат. А не стоит на берегу и кричит «Так а зачем вы нам дали неверные данные? Вот и плывите теперь с тем, что есть. Акты только подпишите о выполненной работе!»
Мы – за результат. И в данном случае нам пришлось вложиться довольно нехилыми дополнительными временными ресурсами с нашей стороны, чтобы по несколько раз получить со всех информацию, перепроверить, найти несоответствия и задать по ним вопросы. А потом ещё раз «прогнать» информацию по всем сотрудникам, чтобы убедиться, что корректировок уже не будет.
И именно в этой работе суть строчки «Подготовка данных к переносу» в нашей смете. И не удивляйтесь её объёму, т.к. вы, как руководитель, скорее всего даже не подозреваете о тех проблемах, с которыми придется столкнуться интегратору для выполнения этой работы. Собственно, в этой статье мы и описываем всё это, чтобы показать прозрачность нашей работы и ориентировку на результат даже в том случае, когда мы что-то недооценили. Просто берём и делаем так, чтобы был результат.
Всё, на этом основная цель этой статьи выполнена. Дальше будет лишь описание конкретно нашего подхода на этом проекте. Ну если вам интересно это почитать.
Погнали…
На самом деле задача свиду простая – в Эксельке разбить всю уникальную информацию по разным столбикам. И потом, глядя на эту простыню информации, определить нужную архитектуру справочников для всей этой информации.
Начинаем с того, что раскидываем ту информацию, что нам дали изначально, а затем отправляем файл клиенту на ДОзаполнение, специально выделяя фоном те ячейки, где нужно изменить информацию:
Так это было по ткани:
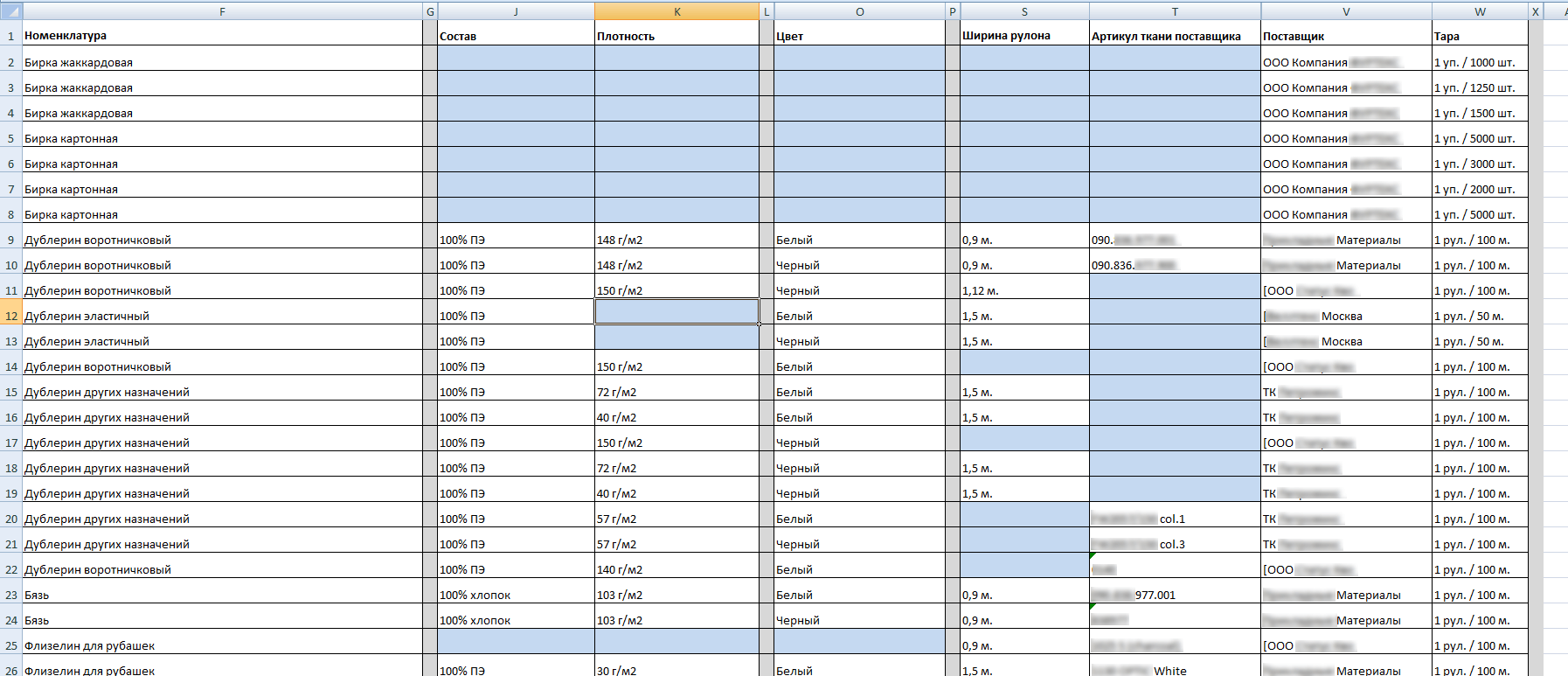
А так по фурнитуре (лишь кусок файла):

Причём вот вам ещё очень важный совет – в любом случае всегда проверяйте, не менял ли клиент информацию в тех ячейках, где вроде бы НЕ должен был ничего не делать (мы же типа цветом указали конкретно места, где можно менять). Потому что логика поведения человека не имеет границ и если он видит, что указана неверная информация в какой-то ячейке (хотя она не выделена для заполнения), он может взять и поменять там данные, НИКАК об этом не уведомив (ни цветом текста, ни фоном ячейки, вообще никак). В итоге вы получите файл с корректировками, о которых даже не догадываетесь.
Поэтому мы после каждого получения файла тщательно сверяли каждый столбик, не было ли там изменений. Потому что они БЫЛИ! Но это стандартная практика, к ней надо привыкнуть и вообще отмечать такие изменения – очень важное дело, т.к. «дьявол кроется в деталях». Если клиент сделал корректировку, значит ранее кто-то указал неверные данные. Почему? И пошли распутывать этот клубок несоответствий. Вот она – ценность работы интегратора.
А ещё, т.к. в нашем случае мы корректировки проводили уже после того, как занесли первичную информацию, нужно было отслеживать корректность занесения новой информации в систему, поэтому у себя мы вели такие заметки, где отмечали на важных контрольных точках, какие последние ID записей (уникальный номер) содержатся в базе. Чтобы понимать, какие были добавлены новые и правильно ли были добавлены:

Особенно «весело», когда в самых вроде очевидных местах (например, список цветов) вдруг выскакивают такие комментарии:

Глаза в такие моменты настолько широко удивляются, что можно спички вставить :).
В итоге в ответ на наши файлы нам прилетают комментарии по корректировкам, а-ля:

Вот тут прямо хорошо видно, насколько понимание интегратора может расходиться с пониманием клиента о названии номенклатуры. Надо всё сверять-перепроверять, обязательно. И потом снова отправлять на получение новых комментариев. Пока они не кончатся, т.к. чем более структурированная получается информация, тем проще самому клиенту найти несостыковки, т.к. они прямо «лезут в глаза» (эффект чего полностью отсутствовал изначально).
И так раз за разом мы приходим к файлу, по которому у всех сотрудников на стороне клиента уже нет комментариев. Бинго – это уже достойный результат, чтобы финально заносить его в систему. Причем мы не обманываем себя надеждами на то, что это 100% корректная информация. Практика показывает, что по мелочи ещё данные будут корректироваться уже в системе, но это будет редко и не так болезненно. Т.е. можно определить, что после плодотворной совместной работы корректность можно привести к 95%. А если пользоваться изначально тем, что вам сходу могут прислать – корректность реально может быть 50-70%. Это критически маленький процент для того, чтобы работать с этим в системе.
Кратко отметим и такие моменты (уже связанные с базой лекал, это отдельная тема), что какой-то информации может и не быть вообще среди полученных данных. Например, модель есть в базе, но по ней нет нигде лекал. Где лекала, ау? Они вообще существуют? Или эта модель настолько старая, что уже и исходников лекал нет?

Обнаружить это – тоже задача интегратора.
Подводя итог, скажем, что все данные были занесены, люди успешно работают и пополняют базу уже нужным образом. Клиент рад, что информация стала очень структурированной и уже нанял второго закупщика, у которого нет мыслей сбежать, потому что «бардак». Это отличный показатель успешности проделанной работы.
На этом у нас всё. В конце хотелось бы ещё раз отметить критические важные моменты для успешного завершения работы «подготовка данных к переносу» со стороны интегратора (полезно будет всем интеграторам, читающий эту статью и сталкивающимися с похожими проблемами):
- Не начинать перенос данных без получения всей информации и уверенности в её корректности. Или понимать возможные риски.
- Обязательно в базе (в случае с ПланФиксом – это справочники) предусмотреть поле ID, которое будет цифренно-уникальным для каждой записи. Так вы сможете понимать, какие записи старые, а какие новые. Сейчас ПланФикс по умолчанию сделал возможность вывода такого системного поля в справочники, это уже прекрасно. Пообещали реализовать вывод и в отчёты. А раз пообещали – точно сделают. За это мы их и любим.
- Определить на стороне клиента того, кто будет утверждать получившуюся структуру со всей информацией по номенклатуре.
- Важно-хитрый момент. По возможности, определить 2го человека, кто может проверить информацию по предыдущему пункту. В нашем случае именно мнение с разных сторон помогло максимально рано выявить несоответствие информации действительности.
- При получении от клиента файла с корректировками перепроверять на возможные изменения ВСЮ информацию в файле, а не только те места, где клиент очевидно должен был чего поменять.
- Готовить предельно простые файлы для клиента. Чем меньше лишней информации – тем лучше. Чем она более структурирована – тем лучше.
- Не быть мудаком и ориентироваться на результат, даже если что-то пошло не так.
У нас всё. Удачи вам в подобных проектах. А мы теперь особенно рады, что у нас есть развёрнутый ответ для клиента на его вопрос по смете «А это нахрен что за строчка? Почему столько стоит?». Потому что мы знаем, о чём говорим.
Сергей, появилось ощущение, что для этих целей гораздо проще и, скорее всего, с меньшими затратами подошла бы 1С (унф, ка).
При этом клиент смог бы настроить распределение затрат, рассчитать фактическую себестоимость, а так же получить все дополнительные преимущества в виде работы с первичкой, взаиморасчетами, банками-кассами и т.д.
1C там тоже сейчас будет внудряться. Но один фиг там тоже пришлось бы в порядок приводить номенклатуру. Неизбежно все к этому должны придти в какой-то момент
Ну а в ПФ это тоже сейчас нужно, на этом прикольные вещи тут завязаны, которые позволяют не терять информацию