

//от лица руководителя компании AffContext
22:51 вечера…
Это идеальное время для того, чтобы написать очередную статью, попивая кофе со сливками, пока вокруг тишина. А потом эту статью несколько раз отредактировать и выложить в сеть следующим утром.
Пишем редко, что хреново. Зато если пишем, то так, чтобы потом по сети расходилось :).
И данная статья будет нетипично-очевидной. Но оооочень полезной для вас.
Нетипично – потому что тема давно избитая. Кто уже только не писал про составление списка минус-слов. Но мы то не любим обычный контент!
Очевидная – потому что после прочтения вы скажите себе “охренеть, как это просто и сколько времени экономит. Почему об этом никто раньше не писал?”
А и действительно, я видал много статей на тему “как собрать минус-слова”, но все они так или иначе сводились к тому, что нужно вручную проделывать огромное количество работы по “выдёргиванию” нужных минус-слов из нецелевых ключевых фраз. И не важно, каким путем – с помощью Key Colleсtor, блокнота, или Excel. С ростом количества фраз для обработки росло и количество времени, необходимого на составление списка минус-слов.
При десятках тысяч фраз возникали мысли “а может нафиг это дело? Основные соберём и ладно?”
Но нет, мы за качество, мы за тщательность, мы за то, что лень – двигатель прогресса :). И именно лень заставила “открыть” этот метод.
Итак, хватит сапопохвалы, дальше всё для вас. Из этой статьи вы узнаете, как за 5 минут подготовить список минус слов, имея лишь:
– список целевых фраз
– список НЕцелевых фраз
Это всё, что нужно. Дальше дело техники. С ростом объёма фраз 5 минут могут превратятся в…7 минут, что всё равно огромная экономия времени по сравнению с обычными методами. При этом качество работы будет получше ручной работы.
———– !!! Важно !!! ———–
В статье много картинок. МНОГО! Сделано для вашего удобства, особенно если вы не профи в контексте. Обилие картинок создаёт ощущение, что здесь описан долгий процесс. Но поверьте, при “набитой руке” этот процесс занимает не более 5-7 минут. А времени экономит на часы. Держите эту мысль в памяти, когда будете просматривать N-дцатую картинку 🙂
———– !!! Важно !!! ———–
Все шаги будут подробно описаны и сопровождены картинками. Для этого я проделаю процедуру составления списка-минус слов для тематики “пластиковые окна” по региону Омску. Приступим!
1) Получаем список всех ключевых фраз
Пока всё очевидно – нужно распарсить (например в Key Collector) нужные нам фразы, чтобы получить полный список ключевых фраз, которые выдаёт Yandex.Wordstat. Очевидные вещи расписывать не буду, предполагается, что итак умеете это делать. Примера ради беру самую основную фразу – “пластиковые окна”.
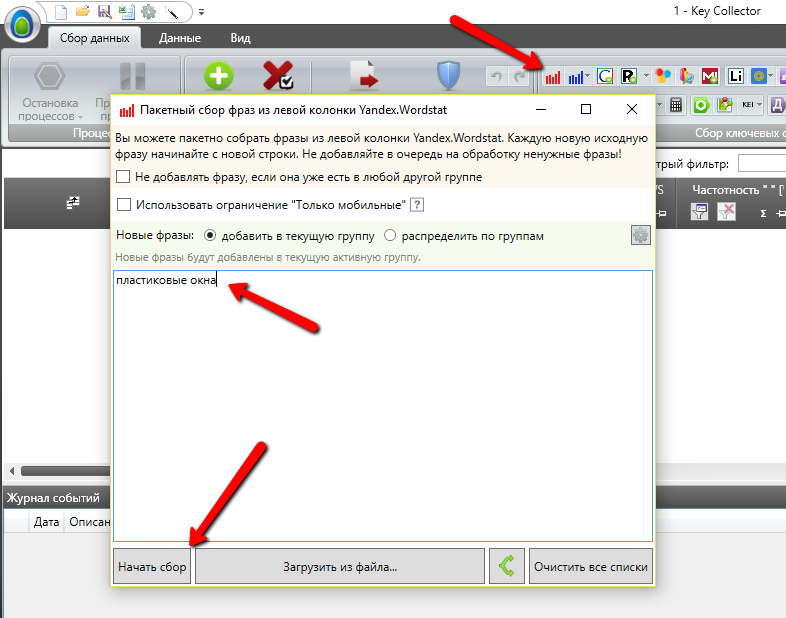
Ждём пару минут и получаем список фраз
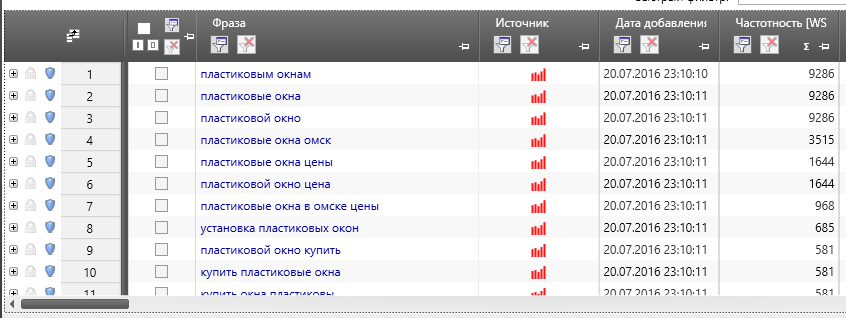
2) Выделяем целевые / нецелевые
Для удобства копируем все эти фразы в новый Excel файл. Можно прямо выделить фразы в Key Collector и дальше как обычно Ctrl-C -> Ctrl-V.
Затем отмечаем, какие фразы являются целевыми, а какие – нет. Лично мы ставим цифру “1”, если фраза целевая, и “0” – если нецелевая. Эту работу всё равно делает каждый, это ещё не ради минус-слов.
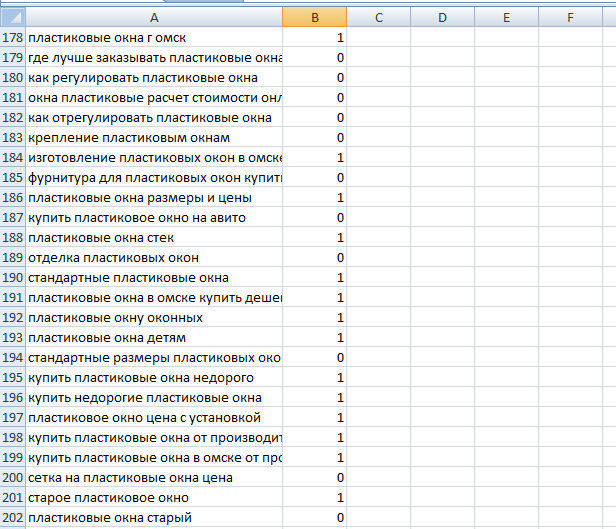
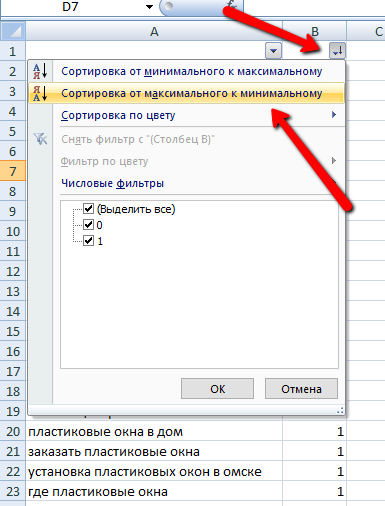
В моём случае всего получилось 217 фраз, из которых 108 целевых и 109 НЕцелевых. Для удобства ещё необходимо отфильтровать все фразы, чтобы целевые остались вверху, нецелевые – внизу.
Вот дальше то начинается самое интересное!
3) Получаем уникальные слова по целевым фразам
Берём сугубо целевые фразы, копируем и вставляем в “Microsoft Word”.
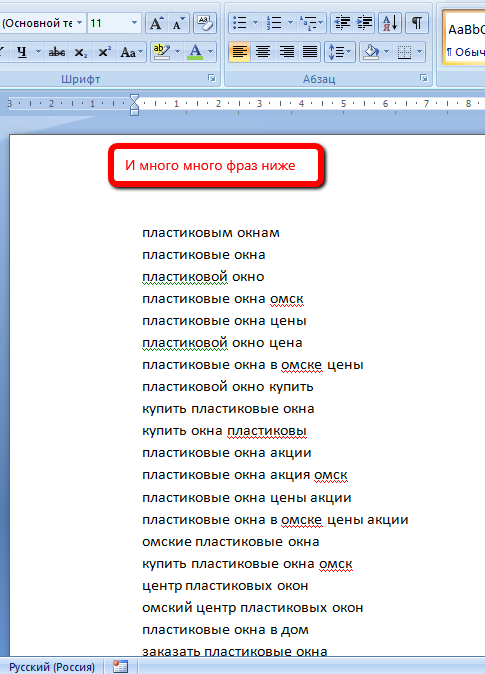
Выделяем все фразы (Ctrl-A) -> Ctrl-H и дальше как на картинке. Меньше текста, больше дела:
{kind=link}
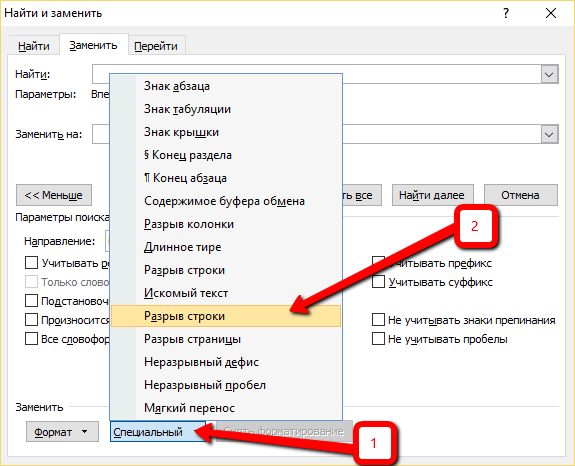
Здесь важно! Убеждаемся, что вы кликнули именно на нужную строку “Разрыв строки” (а то их две на скриншоте выше) и подставился именно нужный знак:
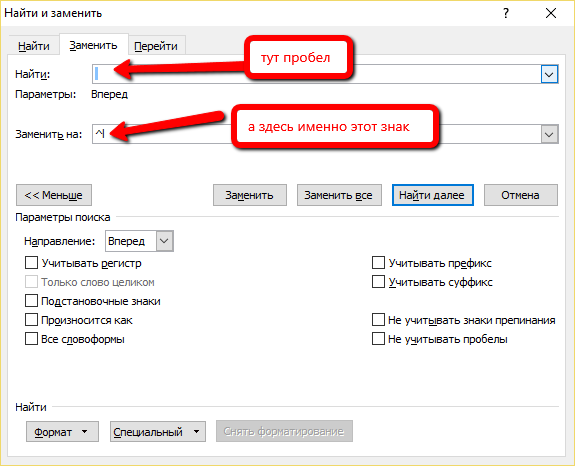
Жмём “Заменить все” и в итоге получаем список одиночных слов, из которых ранее состояли наши ключевые фразы:

4) Удаляем дубликаты по предлогам
Копируем все эти слова обратно в Excel в новый лист. И удаляем дубликаты у этого набора слов:
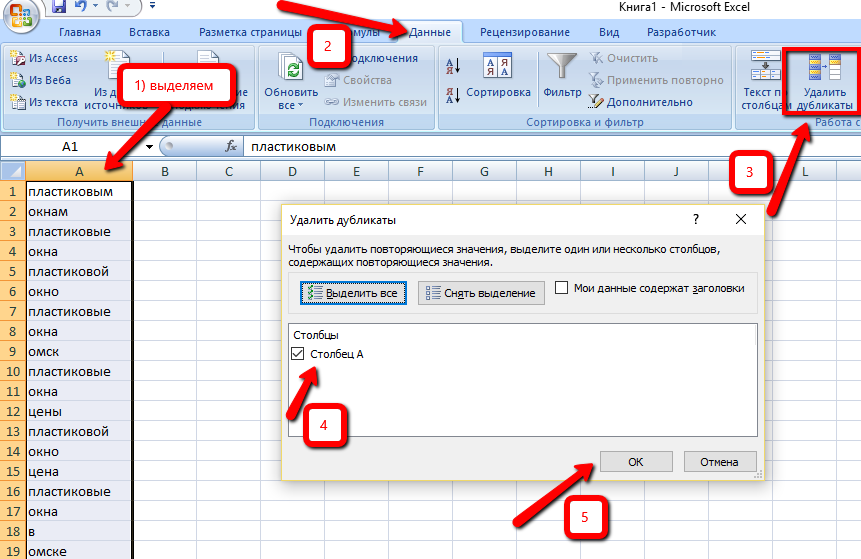
Это нужно для удаления дублей именно по части пробелов. Дальше поймёте, зачем этот этап нужен.
5) Удаляем дубликаты по словоформам
Открываем Direct.Commander. В нашем случае у нас есть отдельный тестовый аккаунт, где мы получаем минус-слова. Для этого лишь нужна ненужная кампания, которую можно загружать на сервер с разным набором ключевых фраз.
Итак, нужна кампания (если нет – создайте, а лучше скопируйте с какой-нибудь рабочей кампании, так быстрее) с одной единственной группой. Назовём эту группу “целевые”. Ведь там будут слова из целевых фраз. В этой группе не должно быть фраз:
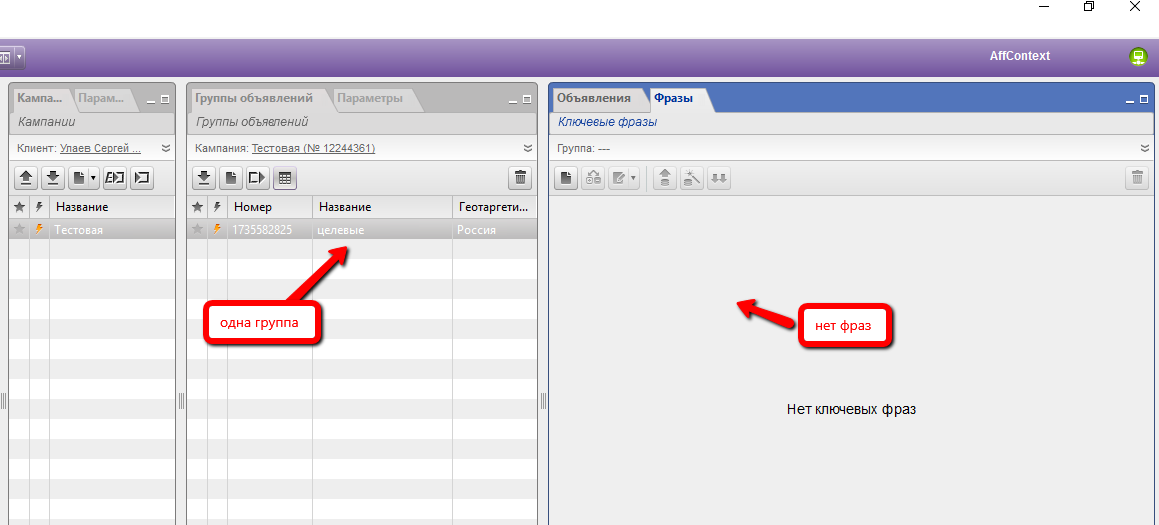
А теперь добавляем наши целевые слова из Excel. Все-все слова, полученные ранее после Word:
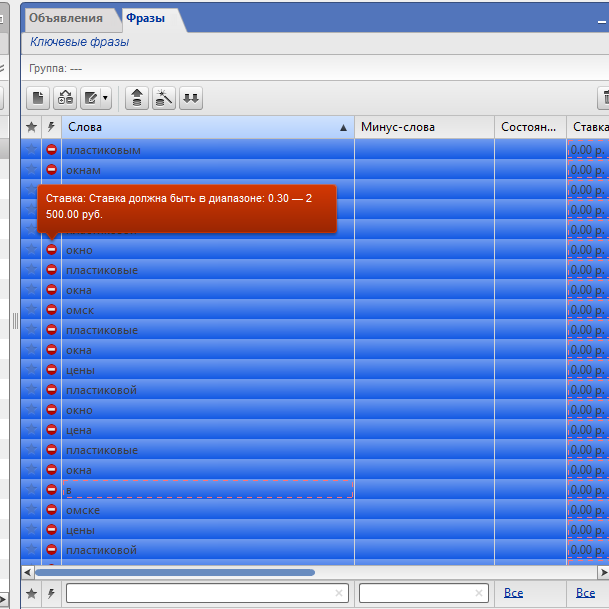{kind=link}
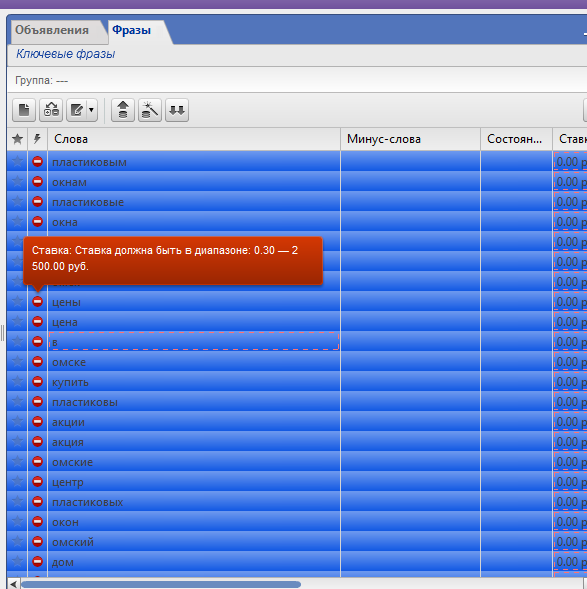
Возле них знак ошибки, это нормально. Нужно лишь выделить все фразы и выставить для них любой ценник:
Теперь ошибок у фраз почти не стало. Почти – потому что у предлогов они до сих пор будут, т.к. Яндекс не может использовать предлог в качестве ключевой фразы для кампании. Кстати, именно таким образом можно и проверять, какие слова из большого списка слов являются предлогами 🙂 :
С ними пока ничего не делаем.
Осталось лишь удалить дубликаты меж этих всех фраз:
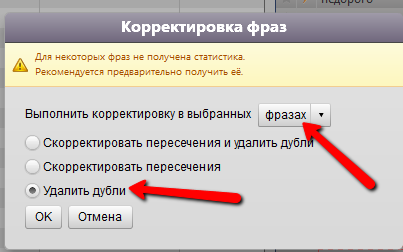
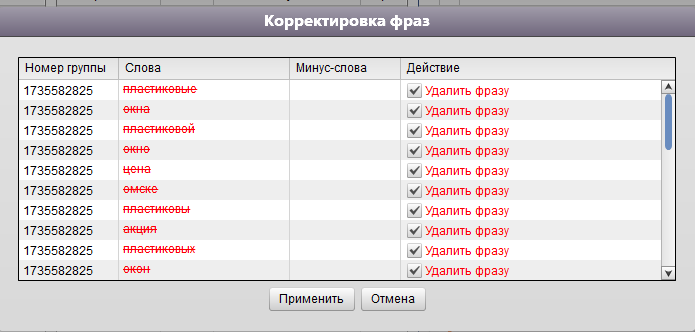
В итоге у нас должен получиться список теперь уже уникальных слов, включая предлоги (которые со знаком ошибки). Это всё хорошо.
6) Повторяем шаги 3-5 для НЕцелевых фраз
Повторяем именно для НЕцелевых фраз (которые в нашем самом первом списке были помечены цифрой “0”). Только в Direct.Commander эти фразы добавляем в другую группу объявлений. Можно просто:
– сделать копию оригинальной группы
– удалить все фразы в ней
– назвать эту группу “грязные”
А дальше все так же, как описано выше, но уже в рамках этой группы “грязные”.
———– !!! Важно !!! ———–
Очень важный момент – нужно делать удаление дублей только в рамках каждой конкретной группы объявлений. Не нужно думать “а зачем лишние шаги, удалю сразу меж обоих групп”, это ломает всю корректность алгоритма. Удаляем дубли у фраз сугубо в рамках каждой отдельной группы объявлений.
———– !!! Важно !!! ———–
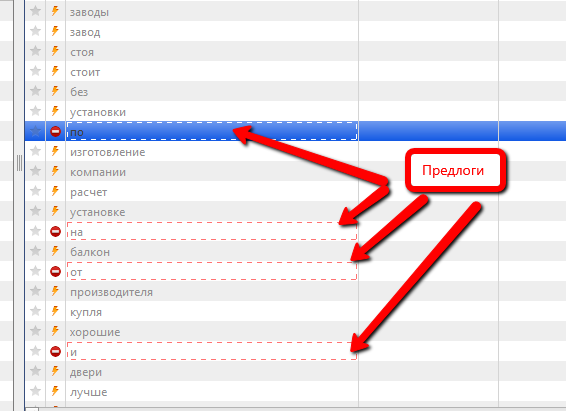
7) Убираем ненужные предлоги
Выделяем обе группы объявлений, в них выделяем все-все фразы. И сортируем по этому полю, чтобы предлоги ушли наверх списка (возможно, придется 2 раза нажать):
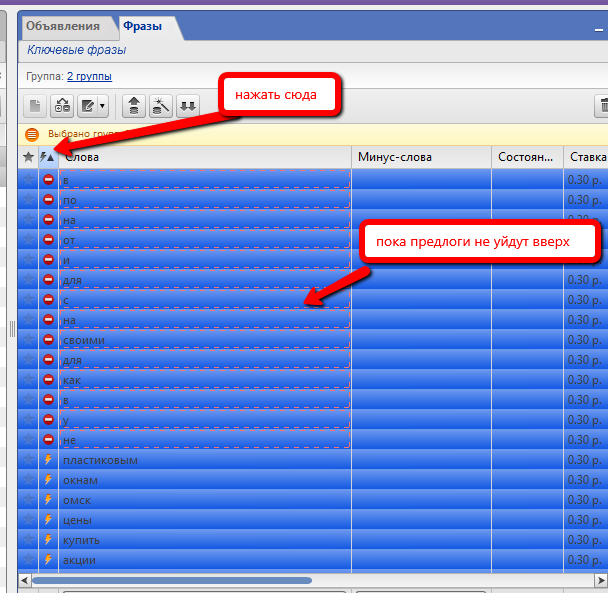
Справедливости ради стоит отметить, что под понятием “предлог” я здесь понимаю всё, что Яндекс НЕ признаёт, как отдельную ключевую фразу. Он туда относит как предлоги, так и местоимения, междометия и прочее.
Казалось бы – надо просто взять их и удалить. Но нет! Среди этих слов могут быть слова, которые нам надо занести в список минус-слов, например, такие:
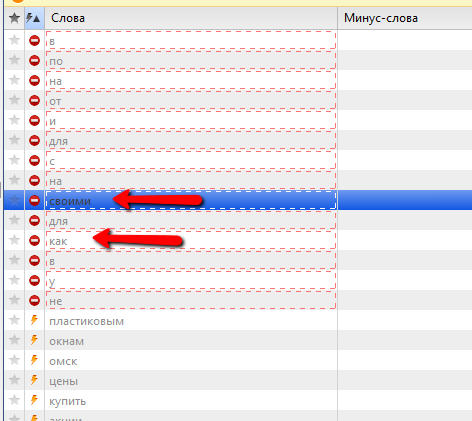
В случае с тематикой пластиковых окон мне не нужны поисковые запросы, где есть слова “своими” и “как”. Скорее всего, люди ищут, как что-то сделать с окнами своими руками. И если бы мы удалили эти слова, они бы потом НЕ попали в список минус-слов.
Чтобы оставить для дальнейшей работы нужные нам слова, нужно перед ними поставить знак “!”. Думаю, вы знаете, что этот синтаксис закрепляет словоформу слова, а в случае с предлогами он как бы говорит “это слово должно быть обязательно. Это не предлог, который можно игнорировать”. Вот и здесь мы помечаем эти слова знаком “!” и они уже становятся как-бы полноценными ключевыми фразами. В нашем случае я ещё зафиксировал слова “для”, т.к. с ними тоже могут быть разного рода запросы, как целевые, так и нецелевые. Но является ли это минус-словом, определит сам Direct.Commander в следующих шагах.
Кстати, именно для этого этапа мы в начале удалили очевидные дубли в Excel. Иначе сейчас бы вы устали просматривать кучу одинаковых предлогов.
Итак, должно получиться так:
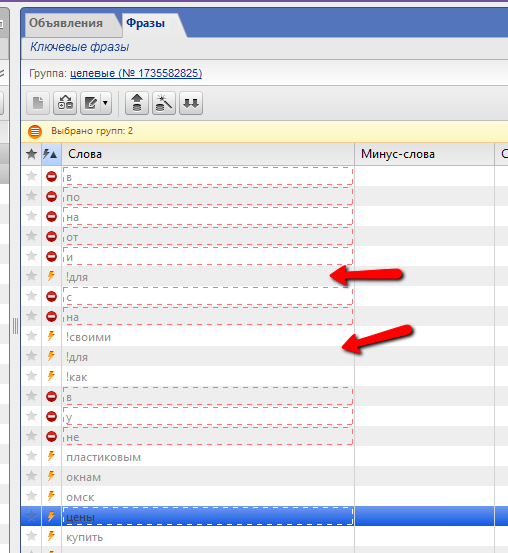
Вот теперь все остальные “предлоги” смело удаляем, они уже нам не нужны. В итоге, мы должны получить 2 группы со словами, без “предлогов” и каких-либо ошибок:
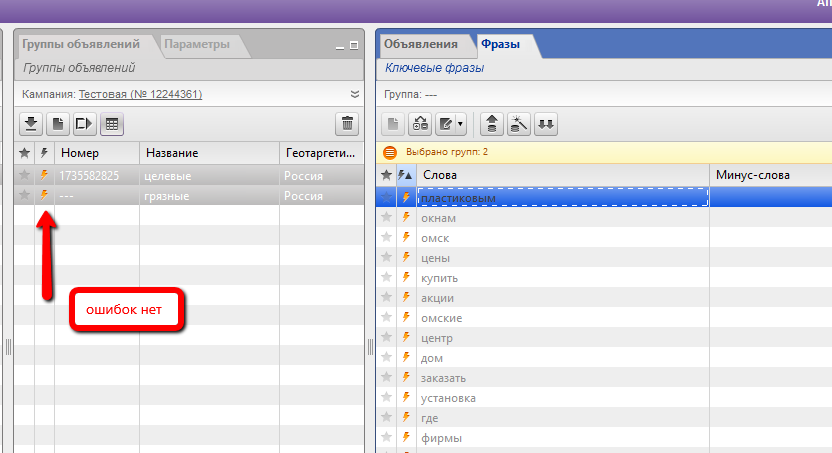
Если всё же есть ошибки, то вы что-то неправильно сделали на предыдущих шагах. Изучайте еще раз ранее сделанное.
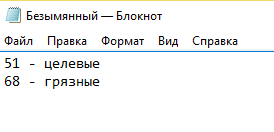
8) Запоминаем количество слов в обеих группах
Просто сделайте это. Для каждой группы. Количество слов можно посмотреть, если выбрать все фразы и нажать сюда:
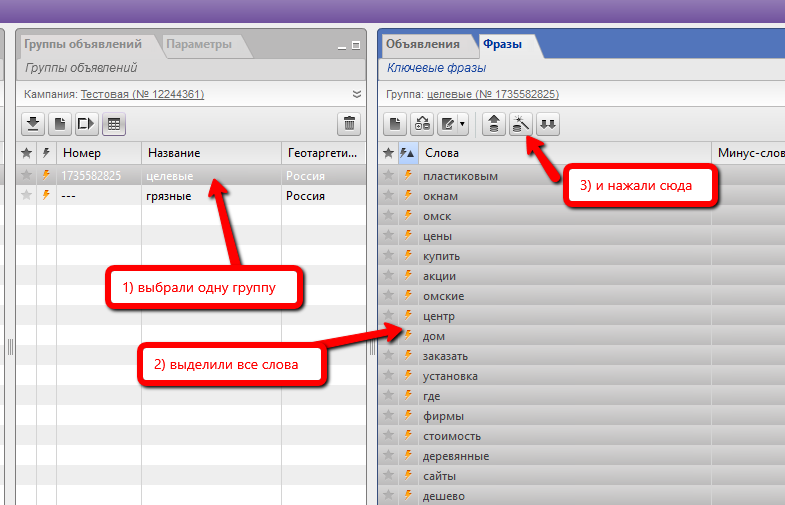
Количество слов будет здесь в скобках:
Где-нибудь (я в блокноте делаю) фиксируем эти значения для каждой группы:
9) Удаление дублей между всех слов
И вот теперь самое основное – выделяем все фразы в обеих группах и удаляем между ними дубликаты:
10) Проверка, что Direct.Commander удалил там, где надо
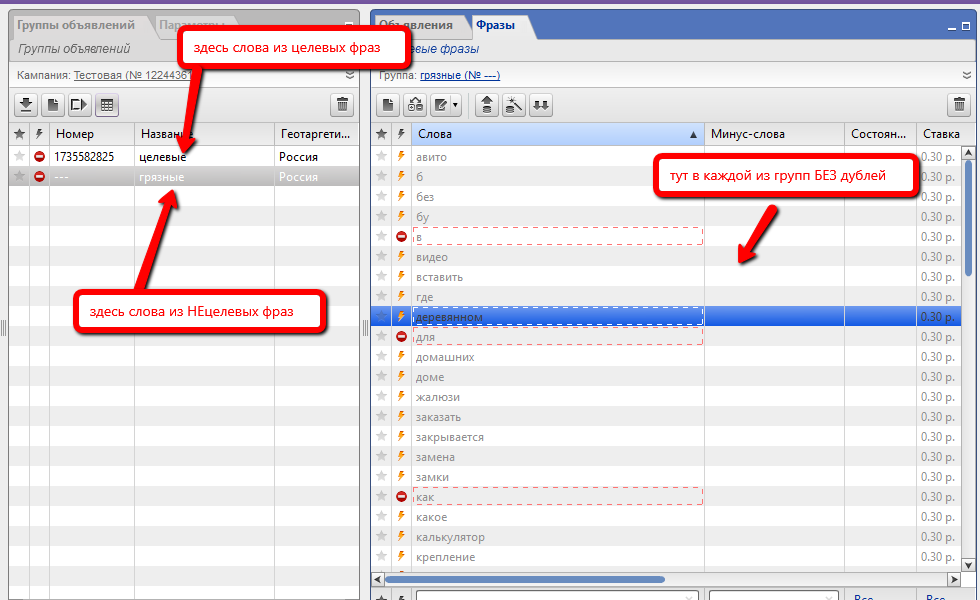
Здесь стоит остановиться на том моменте, что у нас все слова находятся в 2х группах:
“целевые” – здесь находятся слова, которые были в целевых ключевых фразах. Т.е. абсолютно каждое слово из этого списка – целевое и может присутствовать в запросе пользователя.
“грязные” – здесь находятся слова, которые были в НЕцелевых ключевых фразах. Здесь есть как целевые слова, так и НЕцелевые слова, которые и делают всю фразу НЕцелевой. Ведь именно определенные слова дают понимание того, что вся фраза является НЕцелевой.
Так вот, когда мы на прошлом этапе удаляем дубли, то из какой группы должны удалиться дубликаты? Естественно, из группы “грязные”.
И именно для этого мы заранее записали, в какой группе сколько было слов. Итак, теперь снова проверяем количество слов в каждой группе. У меня вышло так:
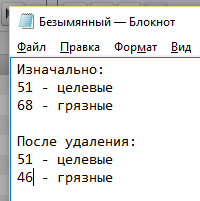
Мы как раз видим, что дубликаты удалились именно из группы “грязные”.
———– !!! Важно !!! ———–
– Ну очевидно же, кэп, что так и было бы
А вот хрен то там! Иногда Direct.Commander почему то удаляет слова из группы “целевые”, что в корне неправильно. Поэтому запомните, что такое возможно. И если так случилось, вам придётся вернуться в эту статью и детально изучить описанный ниже алгоритм.
Иначе, можно мозг сломать в попытках сделать правильно. Собственно, единожды “сломав” мозг, был найден метод, как заставить Direct.Commander делать правильно.
Итак, если у вас слова удалились из группы “целевые”, то нужно сделать следующее:
а) скопировать группу “целевые” и тут же вставить её. В этом случае она окажется под группой “грязные”:
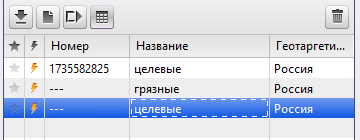
б) скопировать группу “грязные” и тут же вставить её. Она окажется снова в самом низу:
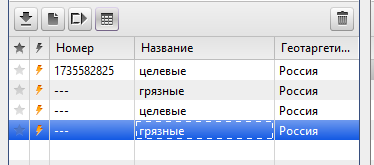
в) удалить верхние 2 группы:
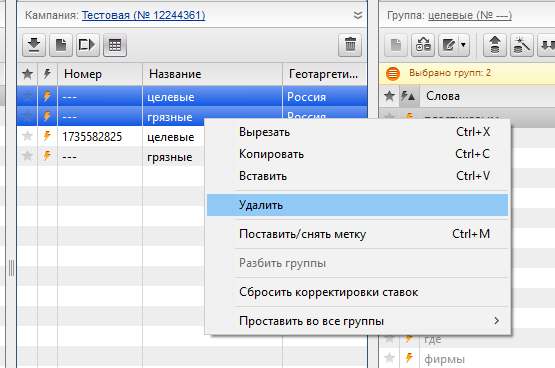
г) снова удалить дубликаты меж групп и проверить корректность удаления
д) если опять удалил неверно, то повторить всю процедуру
Максимум, раз на 5-й, Direct.Commander начинает удалять так, как полагается.
Лучше не спрашивайте, каким образом был найден этот способ :). Считаю, что это было чистой удачей, за что я благодарен судьбе. А то уж не знаю, что бы делал….
———– !!! Важно !!! ———–
Здесь тоже справедливости ради стоит отметить, что почти всегда из группы “целевые” всё же несколько слов удаляется. Обычно, это не больше 5-10 слов. И это нормально! Эта небольшая ошибка исправится на следующих этапах.
Просто следите за тем, чтобы количество удаленных слов было не особо большим. Если их много – значит это алгоритм сработал некорректно.
11) Проверка списка минус-слов вручную
Единственный шаг, где нужно что-то делать вручную.
Выделяем группу “грязные” (в которой остались как раз таки НЕцелевые слова) и выгружаем ее в файл:
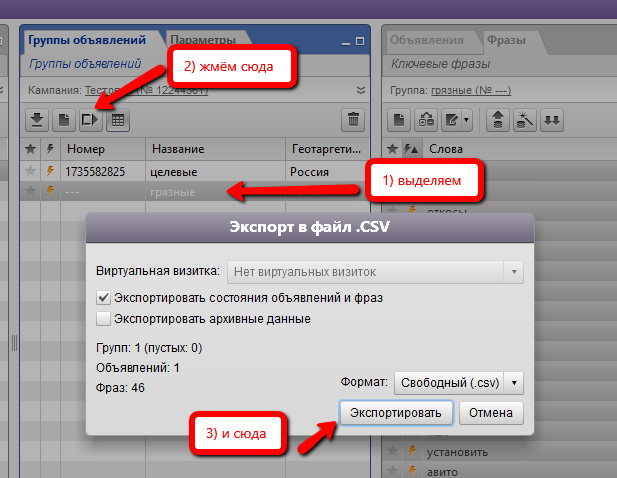
Открываем сохраненный файл и копируем список слов из столбца “Фраза с минус-словами” на отдельный лист. Это сугубо для удобства работы:
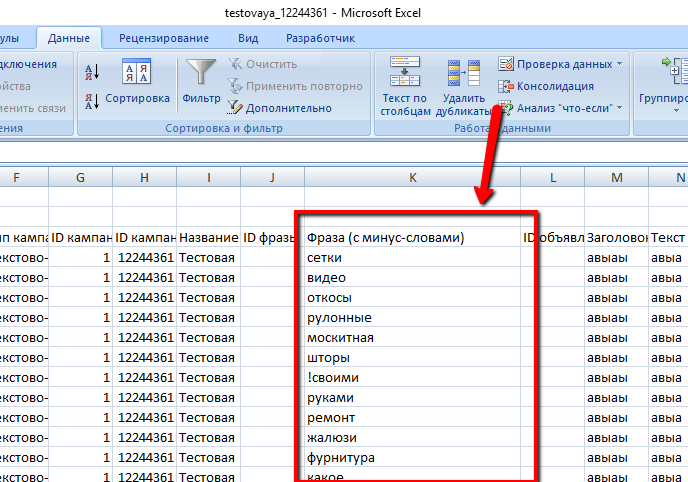
Так же для удобства список слов можно отсортировать:
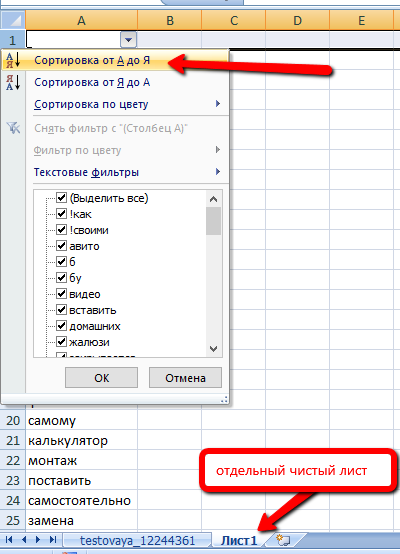
И теперь нужно самому посмотреть все эти слова, т.к. если вы не особо качественно отмечали целевые / нецелевые фразы, то здесь могут оказаться как-раз слова, которые НЕ должны быть в списке минус-слов. Их тогда нужно из этого списка удалить.
Например, вы можете подумать “а чего это слово – установить – сюда попало? Оно вроде бы целевое.”
Просто берём и удаляем это слово из этого списка.
В итоге мы должны получить почти финальный список минус-слов. Но это ещё не все.
12) Проверка минус-слов на пересечение с ключевыми фразами
Вот здесь как раз мы будем исправлять небольшие ошибки того, что из группы “целевые” тоже может удалиться несколько слов на этапе удаления дубликатов. Да и в принципе – это необходимый этап при составлении списка минус-слов любым из способов.
Удаляем в Direct.Commander группу “грязные”. В группе “целевые” удаляем все фразы. Теперь везде пусто.
Берем изначальный список целевых фраз, полученный еще на этапе отмечания целевых/нецелевых фраз, и вставляем эти фразы в группу “целевые”.
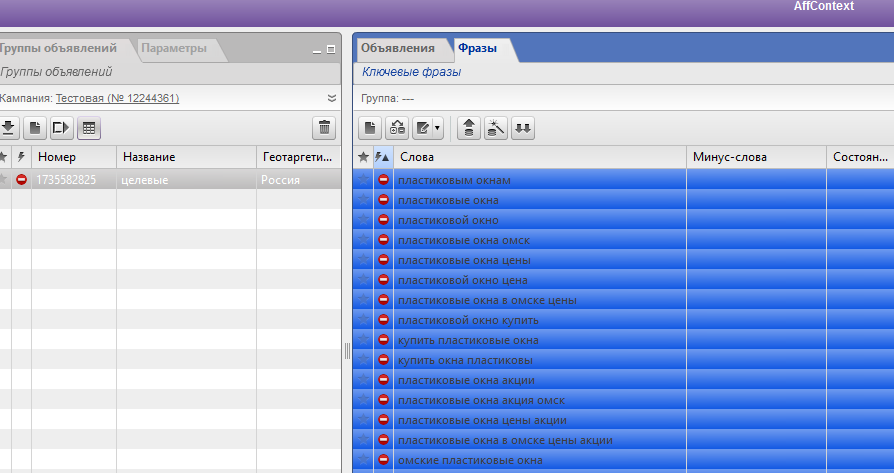
Дальше выставляем для фраз ценник (это вы уже умеете). Если вы идеалист, то можете здесь и дубликаты удалить, чтобы глаз не резали. Но вообще это не влияет на дальнейшие шаги. Я удалю :).
Если будет ошибка на то, что внутри группы много фраз, то разбиваем группу на несколько:
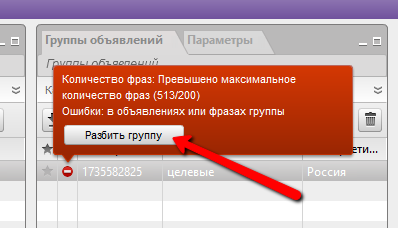
И затем, когда уже Direct.Commander не будет показывать ошибок, отправляем кампанию на сервер.
Идём на сервер и заходим в только что загруженную кампанию. Открываем окно единого списка минус-слов и добавляем туда все те минус-слова, что у нас уже есть:
Конкретно в нашем случае у нас изначально удаление слов прошло очень корректно и система мне не выдала никаких сообщений. Но в большинстве случаев вы может увидеть такое сообщение:

Тогда выписываем отдельно эти слова и находим ключевые фразы, которые содержат эти слова. И тогда варианта 2:
а) ключевые фразы целевые. В списке минус-слов есть ошибочное слово. Тогда удаляем это слово из минус-слов.
б) в списке ключевых фраз есть НЕцелевые фразы. Это промах на этапе отмечания целевых / нецелевых (это норма, особенно когда фраз несколько тысяч). Тогда удаляем саму ключевую фразу.
И потом снова пытаемся добавить список минус-слов. Если он добавился без каких-либо сообщений – то всё, это финал. Никаких пересечений нет и вы получили конечный список минус-слов. Уже можно радоваться 🙂

Под конец несколько замечаний по всему вышеописанному:
а) советую очень-очень тщательно отмечать фразы на целевые / нецелевые. Ибо если допустите много ошибок, то много минус-слов не получите и пропустите, т.к. “грязные” фразы будут у вас в списке “целевых”.
б) если у вас список фраз всего 50-70 штук, то быстрее составить минус-слова вручную, это факт. Но если вам нужно сделать минус-слова из списка 3000 целевых и 5000 нецелевых фраз….ту тут-то вы и полюбите этот метод. Это безумная экономия времени.
в) сейчас вам может показаться, что это какой-то долгий метод. Но это лишь из-за большого количества картинок. Поверьте, практически при любом количестве фраз это занимает всего лишь 5-7 минут времени.
На этом всё.
P.S. После публикации статьи было много однотипных вопросов на одну и ту же тему: “А чем этот метод лучше анализа групп в Key Coolector?”
Ответ: Если работать через функционал «Анализ групп», то:
1) не виден контекст всей фразы сразу. А это особенно важно в незнакомой нише. Нужно над каждой фразой и её контекстом основательно думать
2) для агентств это даёт возможность разбить сами процессы на отдельные независимые шаги, НЕ теряя качество. Будет отдельный процесс по выделению целевых / нецелевых, и отдельный процесс на минусову. Разделение этапов даёт возможность более тщательно отобрать целевые фразы, обсудить с заказчиком, выслать ему файл и порой попросить выделить нужное / ненужное и прочее. Всё это сказывается на удобстве и скорости работы.
А вообще, это дело каждого, какой метод ему выбирать. Вам решать
—————
Если вам понравились наши статьи и вы хотите получать свежие посты на свой e-mail, то просто подпишитесь на нашу рассылку. В левой панели в самом верху страницы (где ссылки и vk-виджет) есть кнопка «Подписаться«. Кликайте на неё!
Так же будем благодарны за репост данной статьи в соц.сетях. Сделано с трудом и любовью к делу.
Спасибо за метод! Очень элегантно.
По поводу того, какую фразу из дублей Директ Коммандер удаляет при корректировке. Где-то в клубе Директа поясняли, какие условия срабатывают и в каком приоритете. Короче, имеет значение:
– возраст фразы (более старшая от момента создания остаётся)
– статистика (больший CTR и большая ставка остаётся),
– что-то ещё…
– возможно имеет место и неточные округления моментов времени или ставок во внутренних вычислениях
И второй совет: копировать фразы из коммандера проще не через экспорт, а через выделение столбца и копирование в буфер.
да, тоже слышал о таких факторах в коммандере. Но он порой глючит даже если кампания только что созданная и все фразы БЕЗ статистики. Увы (
А про второй совет спасибо, учтём
Ознакомился. Очень замороченно, но, как говорится, работает.
На мой взгляд гораздо проще работать в KeyCollector через группировку ключей. Там сразу можно древом отсекать нерелевантные ветки ключевых фраз, раскрыв древо проверить в каких фразах он встречается, ну и корневой ключ заносить в минуса.
Раньше похожим образом мучился в экселе, с KeyCollector все стало гораздо проще.
P.S – KeyCollector не приплачивал за этот комментарий.))
В целом, дело каждого, но анализ групп вам показывает лишь единичные слова. Не знаю как вы, а я по одному лишь отдельному слову не могу сходу сообразить, может оно использоваться в ключевой фразе или не может и добавлять ли его в минуса. Нужен контекст всей фразы. Поэтому мне удобнее проверять именно ключевики, а не отдельные слова. Был случай, когда для 6000 фраз коллектор выдал мне 4000 слов по анализу групп. Тут уже экономии особо точно нет.
Ну и плюсом является то, что можно выделить разные процессы:
1) выделение целевых / нецелевых
2) минусовка
и раздать это разным людям. В случае агентств это упрощает контроль, т.к. можно более детальные инструкции написать, НЕ теряя в качестве. Если делать через коллектор, то сильно будет влияние отношения специалиста к фразе, его настроение. и фазы луны…
Т.к. у нас этап получения целевых фраз – это один из самых важных этапов, то мы на нем делаем сильный упор и детально анализируем фразы
Такого долгого, ненадежного и неудобного способа еще не встречал.
Почему долгий? Реализация не более 5 минут. Не пугайтесь количества картинок. Сделано как раз для тех, кто только начинает с этим разбираться
Интересный материал!
Только вот не ясно на первом шаге при парсинге вордстата. Тут мы парсим и размечаем на целевые/нецелевые всё ядро или только какую-то выборку?
А это уже от вас зависит. Чем больше соберёте, тем больше минус-слов потом на выходе получите. Это лишь зависит от времени, сколько вы потратите на отмечание целевой / нецелевой. Кто-то до частотности 1 собирает все запросы )
А до какой базовой частотности вы собираете? Я обычно ниже 10 не опускаюсь. Если ниша сезонная и теперь не сезон, то тогда до 5 опускаюсь.
А как выделить столбец в коммандере?
В коммандере? Оттуда нельзя фразы копировать. Только из коллектора. Вы же по это или я не так вопрос понял ?
Если просто чтобы отсортировать, то надо кликнуть на заголовок столбца
это дело каждого и влияет на:
1) ваши трудозатраты по обработке всех фраз
3) количество целевых запросов
НО количество этих НЧ фраз вообще может не оказать никакого влияния. На этот счёт рекомендую нашу статью – “50% фраз не имеют показов. Вы серьёзно?”
Мы обычно по регионам собираем до 5, по России – до 10-50
Всё, что ниже 10, из недели в неделю пропадает / появляется в вордстате постоянно
Очень заморочено. Все это делается в KeyCollector или с помощью keysa.ru.
ПКМ по имени любого столбца – “Выделить столбец” – “Копировать столбец”
Думаю в некоторых проектах стоит каждый месяц заново парсить ключи, чтобы найти новые. Это быстро сделать если добавить все минус слова в запрос к вордстату, а затем найденное проверить на дубли в коммандере.
“Копируем все эти слова обратно в Excel в новый лист. И удаляем дубликаты у этого набора слов:
Это нужно для удаления дублей именно по части пробелов. Дальше поймёте, зачем этот этап нужен.”
Во-первых, наверно тут опечатка? пробелов=предлогов
Во-вторых, так и не понял зачем этот этап, если Коммандер удалет ВСЕ дубли, в т.ч. и предлоги.
“Кстати, именно для этого этапа мы в начале удалили очевидные дубли в Excel. Иначе сейчас бы вы устали просматривать кучу одинаковых предлогов.”
Нет одинаковых предлогов, если удалять дубли только Коммандере.
Прошу прощения, действительно Коммандер не удаляет дубли предлогов.
Но опечатка актуальна.
При анализе групп, группу можно развернуть и смотреть какие фразы в ней находятся и постепенно идя в низ сворачивать. И можно делать вывод не по одному слову, а всем фраза его содержащим.
Я только не понял, за счет чего спец будет действовать точнее?
Влад, так здесь схожая логика. Только обработка порой занимает меньше времен. Не нужен сворачивать / разворачивать постоянно, это же тоже действия и время.
Иногда лучше просто глазами весь набор фраз просмотреть. Скорость обработки порой выше.
Опять же – это не уникальный метод. Делается кому как удобнее. Но мы постоянно прибегаем к этому способу, особенно, когда сами заказчики хотят проконтролировать целевые / нецелевые слова. Им проще работать “по старому” в Экселе. Не будешь же их обучать работе с коллектором
А почему в Word не используете заменить пробел на ^p?
На мой взгляд, это быстрее 😉
Ого. Похоже, просто не пробовали )
Не понял вашего метода. Вы сами себе противоречите:
“а) советую очень-очень тщательно отмечать фразы на целевые / нецелевые.
б) … Но если вам нужно сделать минус-слова из списка 3000 целевых и 5000 нецелевых фраз…”
И какая тут экономия времени? Если придется на пункте а) просматривать “очень-очень тщательн” эти 5000 фраз? Это пустая трата времени.
В кк анализ групп по отдельным словам, минусуете массово группы фраз, где более, допустим, 3-х фраз в группе.
А вот список непроверенных фраз уже можно просмотреть вручную в том же КК после отсева уже текущих минусов.
Ctrl+S ускорит вашу работу.
Ваш метод “для ленивых” имеет место быть, когда за вас клиент обрабатывает список на целевые/нецелевые. Т.е. он по сути сделал работу по анализу семантики, а вам остается лишь эффективно выявить минуса.
Больше плюсов не вижу, прочитал внимательно. Времязатраты по пункту а) перечеркивают все преимущества вашего метода.
Или в чем я ошибся?
Т.е., допустим, ядро 10 000 КФ. В ядре присутствуют 50 фраз с наличием “отзывы”, зачем тратить 50 единиц времени на просмотр фразы глазами, ее анализ, отметку нулем. Если это можно сделать при анализе групп в КК одним кликом?
Анализировать, имхо, стоит только фразы, которые не подверглись групповому анализу.
Артём, метод не претендует на звание уникального. Но просто лично МЫ ощущаем, что порой в экселе там сделать быстрее. Думаю, наибольшая эффективность в трудозатратах при ядре в 1000 – 2000 фраз
Тут кому как удобнее.
Но то, что этим можно пользоваться – факт
вот с повторами да – есть такая проблема. Тут не спорим. При 10 000 фраза мы уже и сами сначала уберём все крупные минуса через КК, а потом уже снова через эксель. Ну приноровились мы там )
А за замечание спасибо. По делу
Кстати, уже подумываем по поводу сервиса, который и эту бы проблему для нас решил
Прочитал ваш метод – супер. Давно самостоятельно к этому шел, но немного не дошел). Мне он подходит на 99%.
У нас после парсинга как раз специалист занимается определением целевых и НЕ целевых фраз (с целью последующей кластеризации).
Имея список целевых и НЕ целевых запросов мы делали просто кросс-минусацию на все запросы. И как я понимаю такой способ имеет место быть, до того момента пока запросов не сильно много и мы укладываемся в ограничения по кол-ву символов в одном запросе с учетом минус слов (поправьте если не прав).
Само собой постепенно пришли к тому, что логичней выделить минуса, которые можно привязать сразу ко всей кампании. И вот тут Ваш способ подходит на Ура.
Единственное, не совсем понял, а что мешает, имея 2 списка: целевых и НЕ целевых слов, сравнить их в Екселе же? Т.е. в списке НЕ целевых, отметить те, которые встречаются в целевых и удалить их?
1) похоже, вы первый, кто оценил метод на “ура” )). Буду вот вас показывать в пример
2) мешает то, что словоформы/предлоги так не учтутся